Python读写Excel表格(简单实用)
帖子发表于 :周三 12月 09, 2020 9:59 am
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:giao窝里giao

首先安装两个库:pip install xlrd、pip install xlwt,如果不知道怎么安装,可以去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题多跟里面的人交流,都会解决哦!
1.python读excel——xlrd
2.python写excel——xlwt
1.读excel数据,包括日期等数据
#coding=utf-8
import xlrd
import datetime
from datetime import date
def read_excel():
#打开文件
wb = xlrd.open_workbook(r'test.xlsx')
#获取所有sheet的名字
print(wb.sheet_names())
#获取第二个sheet的表明
sheet2 = wb.sheet_names()[1]
#sheet1索引从0开始,得到sheet1表的句柄
sheet1 = wb.sheet_by_index(0)
rowNum = sheet1.nrows
colNum = sheet1.ncols
#s = sheet1.cell(1,0).value.encode('utf-8')
s = sheet1.cell(1,0).value
#获取某一个位置的数据
# 1 ctype : 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
print(sheet1.cell(1,2).ctype)
print(s)
#print(s.decode('utf-8'))
#获取整行和整列的数据
#第二行数据
row2 = sheet1.row_values(1)
#第二列数据
cols2 = sheet1.col_values(2)
#python读取excel中单元格内容为日期的方式
#返回类型有5种
for i in range(rowNum):
if sheet1.cell(i,2).ctype == 3:
d = xlrd.xldate_as_tuple(sheet1.cell_value(i,2),wb.datemode)
print(date(*d[:3]),end='')
print('\n')
if __name__ == '__main__':
read_excel()~
运行效果
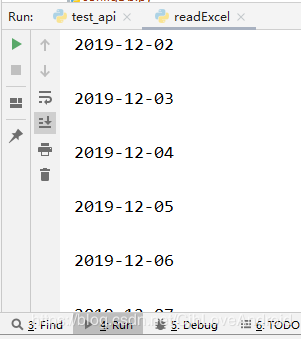
2.往excel写入数据
#coding=utf-8
import xlwt
#设置表格样式
def set_stlye(name,height,bold=False):
#初始化样式
style = xlwt.XFStyle()
#创建字体
font = xlwt.Font()
font.bold = bold
font.colour_index = 4
font.height = height
font.name =name
style.font = font
return style
#写入数据
def write_excel():
f = xlwt.Workbook()
#创建sheet1
sheet1 = f.add_sheet(u'sheet1',cell_overwrite_ok=True)
row0 = [u'业务',u'状态',u'北京',u'上海',u'广州',u'深圳',u'状态小计',u'合计']
column0 = [u'机票',u'船票',u'火车票',u'汽车票',u'其他']
status = [u'预定',u'出票',u'退票',u'业务小计']
for i in range(0,len(row0)):
sheet1.write(0,i,row0,set_stlye("Time New Roman",220,True))
i,j = 1,0
while i <4*len(column0): #控制循环:每次加4
#第一列
sheet1.write_merge(i,i+3,0,0,column0[j],set_stlye('Arial',220,True))
#最后一列
sheet1.write_merge(i,i+3,7,7)
i += 4
sheet1.write_merge(21,21,0,1,u'合计',set_stlye("Time New Roman",220,True))
i=0
while i<4*len(column0): #控制外层循环:每次加4
for j in range(0,len(status)): #控制内层循环:设置每一行内容
sheet1.write(i+j+1,1,status[j])
i += 4
#创建sheet2
sheet2 = f.add_sheet(u'sheet2',cell_overwrite_ok=True)
row0 = [u'姓名',u'年龄',u'出生日期',u'爱好',u'关系']
column0 = [u'UZI',u'Faker',u'大司马',u'PDD',u'冯提莫']
#生成第一行
for i in range(0,len(row0)):
sheet2.write(0,i,row0,set_stlye('Times New Roman',220,True))
#生成第一列
for i in range(0,len(column0)):
sheet2.write(i+1,0,column0,set_stlye('Times New Roman',220,True))
f.save('data.xls')
if __name__ == '__main__':
write_excel()~
在data.xls种生成了sheet1和sheet2:
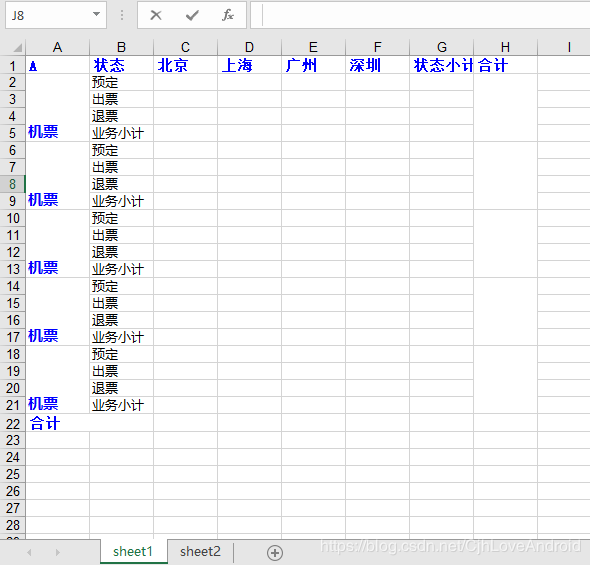
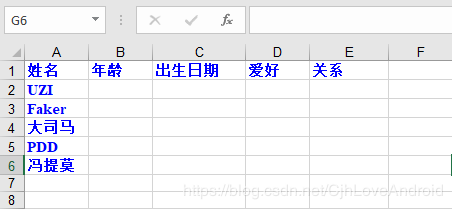
本次分享结束,如果你还有不懂的,可以去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题多跟里面的人交流,都会解决哦!
python3+xlrd解析Excel
# -*- coding: utf-8 -*-
import xlrd
def open_excel(file = 'file.xls'):#打开要解析的Excel文件
try:
data = xlrd.open_workbook(file)
return data
except Exception as e:
print(e)
def excel_by_index(file = 'file.xls', colindex = 0, by_index = 0):#按表的索引读取
data = open_excel(file)#打开excel文件
tab = data.sheets()[by_index]#选择excel里面的Sheet
nrows = tab.nrows#行数
ncols = tab.ncols#列数
colName = tab.row_values(colindex)#第0行的值
list = []#创建一个空列表
for x in range(0, nrows):
row = tab.row_values(x)
if row:
app = {}#创建空字典
for y in range(0, ncols):
app [ colName[y] ] = row[y]
list.append(app)
return list
def read_excel(file = 'file.xls', by_index = 0):#直接读取excel表中的各个值
data = open_excel(file)#打开excel文件
tab = data.sheets()[by_index]#选择excel里面的Sheet
nrows = tab.nrows#行数
ncols = tab.ncols#列数
for x in range(0, nrows):
for y in range(0, ncols):
value = tab.cell(x,y).value
print(tab.cell(x, y).value)
def main():
# print('input the path of your file:')
# a = open_excel(r'D:\smt_ioe\untitled\analysis_excel\my.xls')
# print(a)
b = excel_by_index(r'D:\smt_ioe\untitled\analysis_excel\my.xls', 0, 2)
m = []
for i in range(b.__len__()):
c = b
# a = c['name']
for x in c:
if x == 'date':
print(x)
print('meng')
read_excel(r'D:\smt_ioe\untitled\analysis_excel\my.xls',2)
if __name__ == '__main__':
main()
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:giao窝里giao
首先安装两个库:pip install xlrd、pip install xlwt,如果不知道怎么安装,可以去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题多跟里面的人交流,都会解决哦!
1.python读excel——xlrd
2.python写excel——xlwt
1.读excel数据,包括日期等数据
#coding=utf-8
import xlrd
import datetime
from datetime import date
def read_excel():
#打开文件
wb = xlrd.open_workbook(r'test.xlsx')
#获取所有sheet的名字
print(wb.sheet_names())
#获取第二个sheet的表明
sheet2 = wb.sheet_names()[1]
#sheet1索引从0开始,得到sheet1表的句柄
sheet1 = wb.sheet_by_index(0)
rowNum = sheet1.nrows
colNum = sheet1.ncols
#s = sheet1.cell(1,0).value.encode('utf-8')
s = sheet1.cell(1,0).value
#获取某一个位置的数据
# 1 ctype : 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
print(sheet1.cell(1,2).ctype)
print(s)
#print(s.decode('utf-8'))
#获取整行和整列的数据
#第二行数据
row2 = sheet1.row_values(1)
#第二列数据
cols2 = sheet1.col_values(2)
#python读取excel中单元格内容为日期的方式
#返回类型有5种
for i in range(rowNum):
if sheet1.cell(i,2).ctype == 3:
d = xlrd.xldate_as_tuple(sheet1.cell_value(i,2),wb.datemode)
print(date(*d[:3]),end='')
print('\n')
if __name__ == '__main__':
read_excel()~
运行效果
2.往excel写入数据
#coding=utf-8
import xlwt
#设置表格样式
def set_stlye(name,height,bold=False):
#初始化样式
style = xlwt.XFStyle()
#创建字体
font = xlwt.Font()
font.bold = bold
font.colour_index = 4
font.height = height
font.name =name
style.font = font
return style
#写入数据
def write_excel():
f = xlwt.Workbook()
#创建sheet1
sheet1 = f.add_sheet(u'sheet1',cell_overwrite_ok=True)
row0 = [u'业务',u'状态',u'北京',u'上海',u'广州',u'深圳',u'状态小计',u'合计']
column0 = [u'机票',u'船票',u'火车票',u'汽车票',u'其他']
status = [u'预定',u'出票',u'退票',u'业务小计']
for i in range(0,len(row0)):
sheet1.write(0,i,row0,set_stlye("Time New Roman",220,True))
i,j = 1,0
while i <4*len(column0): #控制循环:每次加4
#第一列
sheet1.write_merge(i,i+3,0,0,column0[j],set_stlye('Arial',220,True))
#最后一列
sheet1.write_merge(i,i+3,7,7)
i += 4
sheet1.write_merge(21,21,0,1,u'合计',set_stlye("Time New Roman",220,True))
i=0
while i<4*len(column0): #控制外层循环:每次加4
for j in range(0,len(status)): #控制内层循环:设置每一行内容
sheet1.write(i+j+1,1,status[j])
i += 4
#创建sheet2
sheet2 = f.add_sheet(u'sheet2',cell_overwrite_ok=True)
row0 = [u'姓名',u'年龄',u'出生日期',u'爱好',u'关系']
column0 = [u'UZI',u'Faker',u'大司马',u'PDD',u'冯提莫']
#生成第一行
for i in range(0,len(row0)):
sheet2.write(0,i,row0,set_stlye('Times New Roman',220,True))
#生成第一列
for i in range(0,len(column0)):
sheet2.write(i+1,0,column0,set_stlye('Times New Roman',220,True))
f.save('data.xls')
if __name__ == '__main__':
write_excel()~
在data.xls种生成了sheet1和sheet2:
本次分享结束,如果你还有不懂的,可以去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题多跟里面的人交流,都会解决哦!
python3+xlrd解析Excel
# -*- coding: utf-8 -*-
import xlrd
def open_excel(file = 'file.xls'):#打开要解析的Excel文件
try:
data = xlrd.open_workbook(file)
return data
except Exception as e:
print(e)
def excel_by_index(file = 'file.xls', colindex = 0, by_index = 0):#按表的索引读取
data = open_excel(file)#打开excel文件
tab = data.sheets()[by_index]#选择excel里面的Sheet
nrows = tab.nrows#行数
ncols = tab.ncols#列数
colName = tab.row_values(colindex)#第0行的值
list = []#创建一个空列表
for x in range(0, nrows):
row = tab.row_values(x)
if row:
app = {}#创建空字典
for y in range(0, ncols):
app [ colName[y] ] = row[y]
list.append(app)
return list
def read_excel(file = 'file.xls', by_index = 0):#直接读取excel表中的各个值
data = open_excel(file)#打开excel文件
tab = data.sheets()[by_index]#选择excel里面的Sheet
nrows = tab.nrows#行数
ncols = tab.ncols#列数
for x in range(0, nrows):
for y in range(0, ncols):
value = tab.cell(x,y).value
print(tab.cell(x, y).value)
def main():
# print('input the path of your file:')
# a = open_excel(r'D:\smt_ioe\untitled\analysis_excel\my.xls')
# print(a)
b = excel_by_index(r'D:\smt_ioe\untitled\analysis_excel\my.xls', 0, 2)
m = []
for i in range(b.__len__()):
c = b
# a = c['name']
for x in c:
if x == 'date':
print(x)
print('meng')
read_excel(r'D:\smt_ioe\untitled\analysis_excel\my.xls',2)
if __name__ == '__main__':
main()